ConcurrentHashMap for Caching
Optimizing Caching with ConcurrentHashMap: Harnessing Concurrent Capabilities for High-Performance Applications
](https://cdn-images-1.medium.com/max/NaN/0*8RArEzlUNBWkFHD5.png)
Introduction
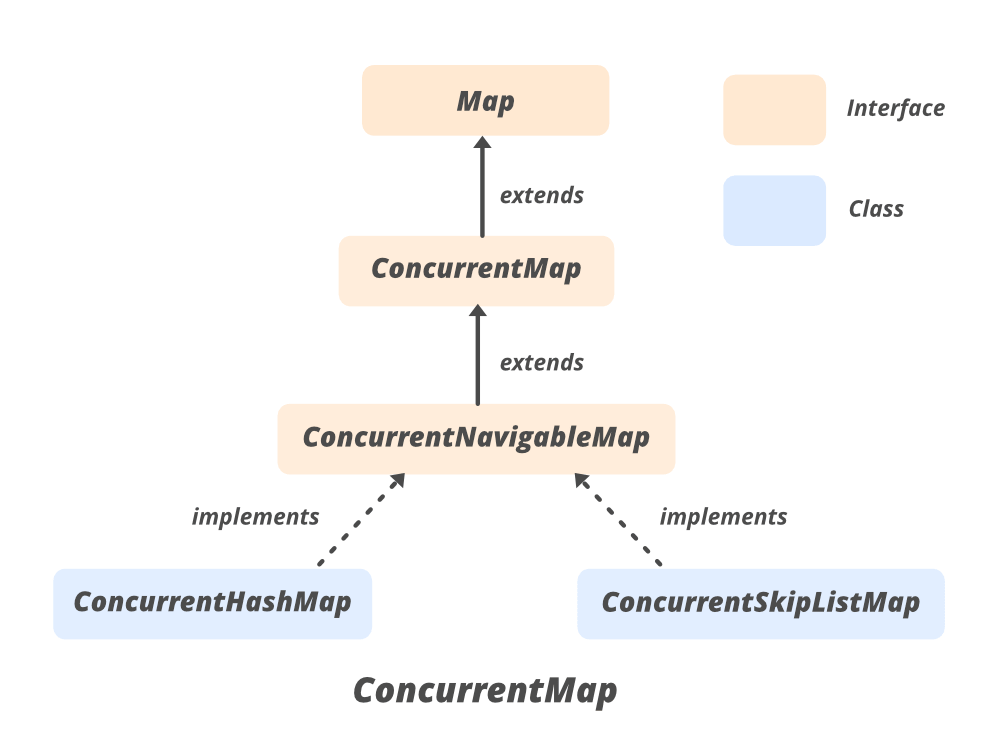
In a previous article, we explored the fundamentals of ConcurrentHashMap, a thread-safe implementation of the Map interface designed to handle high concurrency levels. **ConcurrentHashMap **provides efficient performance in multi-threaded environments by allowing concurrent access and updates without requiring explicit synchronization. This capability makes it a valuable tool for various applications where thread safety and performance are critical.
One of the most compelling use cases for **ConcurrentHashMap **is implementing caches. Caches are essential components in many systems, serving to store frequently accessed data in memory for quick retrieval, thus improving performance and reducing the load on underlying data sources. In this article, we will delve deeper into the use of **ConcurrentHashMap **for caching, examining different caching strategies and their implementation.
Why Use ConcurrentHashMap for Caching?
Caching is a technique used to store data temporarily to reduce the time required to access that data in the future. In a multi-threaded application, implementing a cache that can be safely accessed and modified by multiple threads simultaneously is challenging. Traditional synchronization mechanisms can lead to performance bottlenecks due to contention among threads. **ConcurrentHashMap **addresses these challenges by providing:
Thread Safety: Built-in mechanisms to ensure safe concurrent access.
Performance: Optimized for high concurrency, reducing contention through internal mechanisms like lock striping.
Simplicity: Easy-to-use API that integrates seamlessly with existing Java applications.
](https://cdn-images-1.medium.com/max/2000/0*22FXqhzIUeDKPa0h)
Key Features of ConcurrentHashMap for Caching
Before we dive into specific examples, let’s highlight some key features of **ConcurrentHashMap **that make it suitable for caching:
Atomic Operations: Methods like putIfAbsent, remove, replace, and **computeIfAbsent **allow atomic updates to the map, ensuring consistency without explicit locks.
Concurrency Level: Although the **concurrencyLevel **parameter is deprecated in Java 8 and beyond, the internal design still allows efficient concurrent updates.
Scalability: Designed to scale with the number of threads, making it ideal for high-concurrency environments.
Non-Blocking Reads: Read operations are generally non-blocking, enhancing performance when reads dominate.
Use Cases for ConcurrentHashMap Caching
1. Basic In-Memory Cache
A basic in-memory cache stores key-value pairs and provides fast access to the data. This is suitable for scenarios where the data is frequently read and less frequently updated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
public class BasicCache<K, V> {
private final ConcurrentMap<K, V> cache = new ConcurrentHashMap<>();
public V get(K key) {
return cache.get(key);
}
public V putIfAbsent(K key, V value) {
return cache.putIfAbsent(key, value);
}
public boolean remove(K key, V value) {
return cache.remove(key, value);
}
public boolean replace(K key, V oldValue, V newValue) {
return cache.replace(key, oldValue, newValue);
}
}
2. Expiring Cache Entries
In many applications, it is important to ensure that cached data is not stale. An expiring cache automatically removes entries after a specified period.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import java.util.concurrent.*;
import java.util.function.Function;
public class ExpiringCache<K, V> {
private final ConcurrentMap<K, V> cache = new ConcurrentHashMap<>();
private final ConcurrentMap<K, Long> timestamps = new ConcurrentHashMap<>();
private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
private final long expirationDuration;
private final TimeUnit timeUnit;
public ExpiringCache(long expirationDuration, TimeUnit timeUnit) {
this.expirationDuration = expirationDuration;
this.timeUnit = timeUnit;
scheduler.scheduleAtFixedRate(this::removeExpiredEntries, expirationDuration, expirationDuration, timeUnit);
}
public V get(K key) {
return cache.get(key);
}
public V put(K key, V value) {
timestamps.put(key, System.nanoTime());
return cache.put(key, value);
}
public V putIfAbsent(K key, V value) {
timestamps.putIfAbsent(key, System.nanoTime());
return cache.putIfAbsent(key, value);
}
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
timestamps.putIfAbsent(key, System.nanoTime());
return cache.computeIfAbsent(key, k -> {
V value = mappingFunction.apply(k);
timestamps.put(k, System.nanoTime());
return value;
});
}
public boolean remove(K key, V value) {
timestamps.remove(key);
return cache.remove(key, value);
}
private void removeExpiredEntries() {
long expirationThreshold = System.nanoTime() - timeUnit.toNanos(expirationDuration);
for (K key : timestamps.keySet()) {
if (timestamps.get(key) < expirationThreshold) {
timestamps.remove(key);
cache.remove(key);
}
}
}
public void shutdown() {
scheduler.shutdown();
}
}
3. Loading Cache
A loading cache automatically retrieves and stores values when they are missing. This is particularly useful for read-heavy applications where missing data can be fetched from a database or another data source.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.function.Function;
public class LoadingCache<K, V> {
private final ConcurrentMap<K, V> cache = new ConcurrentHashMap<>();
private final Function<K, V> loader;
public LoadingCache(Function<K, V> loader) {
this.loader = loader;
}
public V get(K key) {
return cache.computeIfAbsent(key, loader);
}
public V putIfAbsent(K key, V value) {
return cache.putIfAbsent(key, value);
}
public boolean remove(K key, V value) {
return cache.remove(key, value);
}
public boolean replace(K key, V oldValue, V newValue) {
return cache.replace(key, oldValue, newValue);
}
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
return cache.computeIfAbsent(key, mappingFunction);
}
public V merge(K key, V value, java.util.function.BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
return cache.merge(key, value, remappingFunction);
}
}
Conclusion
Using **ConcurrentHashMap **for caching provides a powerful and efficient solution for managing concurrent access to cached data. Whether implementing a basic in-memory cache, an expiring cache, or a loading cache, **ConcurrentHashMap **offers the necessary thread-safety and performance characteristics. By leveraging its atomic operations and non-blocking reads, developers can build scalable and responsive applications that handle concurrent data access with ease.
Review my simple cache library.